
Data warehouse technologies are a vital part of modern data analytics and machine learning. What is a data warehouse and how does it apply to your business?
This article provides a high level business explanation for a data warehouse and introduces some of what a data warehouse can do for your business.
- Background
- Architecture
- Data Preparation
- Data Mining / Machine Learning
[read more=”Read more” less=”Read less”]
Background
What is a database?
 Firstly it’s important to understand what a database is.
Firstly it’s important to understand what a database is.
I’ve put a technical article together here which you might try having a read which provides some background.
In short, a database is a storage of information usually as a result of some action happening. In business terms, you sell something, you make a phone call, you send an email all the transactions therefore a record should end up in a database whereby counting and analysing this data you can improve business decision making.
Businesses need different approaches to databases for different scenarios due to the type of content being stored, frequency of updates and levels of analysis required.
In the same way you don’t keep groceries in a library and vice versa, choosing the right type of database for the job has benefits.
Why data mining now?
Data mining’s growth is fueled by several factors:
- Explosive growth in data collection
- The storage of enterprise-wide data in data warehouses
- Increased availability of Web click-stream data
- The tremendous growth in computing power and storage capacity
- Development of off-the-shelf commercial data mining software products
In short the entire area has become a lot more accessible and companies who can leverage answers hidden in the data save millions on research and failed try and test experimentation.
OLAP Vs. OLTP
Let’s use an analogy. A busy grocery shop has a till. The assistants swipe everything sold which goes into the database.
This is a high volume database storing lots of little bits of information referred to as an OnLine Transaction Processing system or OLTP.
There are many grocery shops working together in the collective furthermore requiring managers to generate a report every day on all their shops. Shops send their data to the central warehouse to make reporting easier.
A database used for analysis, where the bulk of the information does not change frequently, is referred to as an OnLine Analytical Processing system.
Your OLTPs around your business in sales or production generally will feed into the big data warehouse, your OLTP system.
Some industry jargon
Big data is quite simply all of your operational data in one place and available to computer systems to be able to go through it. Whilst a till may keep a week or so of data, a warehouse could keep years and years of data.
To help you picture it, think the warehouse at the end of the movie Indiana Jones and the Raiders of the Lost Ark.
Dark data is exactly the same data but information you’re not using or analysing therefore meaning you have the data, you just don’t use it.
Bad data is the bane of a warehouse existence. Once stored bad data can cause chose so checking it on the way in from the OLTPs into the warehouse is the best chance of correcting issues before the happen.
Bad data can cause very difficult situations. https://www.nytimes.com/1983/07/30/us/jet-s-fuel-ran-out-after-metric-conversion-errors.html
Architecture
The elements of a data warehouse
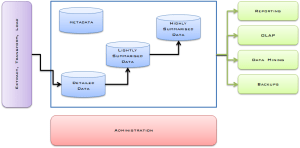
ETL or Inputs
The purple box is the “Extract Transform Load” or ETL process.
Oracle coined ETL expression for their data warehouse solutions. The expression carries over as a general process of getting data into a data warehouse regardless of the specific management system.
Your organisation extracts data from various systems that generate metrics. The data goes through a transformation process to make sure everything is the same for the warehouse. The warehouse avoids bad bad by properly cleaning the data on the way in. If one system provides amounts in litres and the other system uses gallons the transform process will need to do the conversion. Load means move the data into the Detailed Data section and kick off the Summarisation processes.
Sources of data need specialised sets of rules needs built for them usually called Connectors.
Administration
The red Administration box represents the administration system used to look after the warehouse. You use this program to configure the settings of the warehouse as you use Microsoft Word to write documents. If you have a database you will have a DBMS, or DataBase Management System, to manage it. Administration is the warehouse version of that.
Data
Within the warehouse there are usually four distinct groups of data.
- Detailed data is low level data which usually comes from the OLTP systems. Every product scanned in at the tills.
- Lightly Summarised Data. This is the first level of time saving. The warehouse summates the most frequently used metrics therefore the system doesn’t have to count up all the items every time this figure is needed in a report. An example light summation for our grocery store might be “total sales for a day in one store”.
- Highly Summarised Data takes this a step further and usually for longer periods. All sales by store for a month might be an example.
- MetaData is data about data. How many records are in the warehouse? When did the system last receive data? That kind of metadata.
The Summarised Data settings are tweaked by DBAs (DataBase Administrators) who optimise the output requirements of the warehouse using the Administration software.
Outputs
The green boxes are the outputs you can get from the warehouse
- Reporting is basic reports that you might get from other systems with the benefit that all the business data is in one place.
- OLAP or Online Analytical Processing is a set of reporting tools which are interactive in nature. OLAP performs complex calculations, trend analysis and other processes very quickly on the data.
- Data Mining is a collective term which consists of a set of algorithms (mathematical programs) that go into the data to find patterns. It is discussed in detail below.
- Backups do what they say on the tin.
Data Preparation in ETL
Cleaning data
 You may think it looks the same but the computer may see it very differently.
You may think it looks the same but the computer may see it very differently.
When you load your data you may not have all the information you want.
You might be waiting for people to fill out reports as a result you may have incomplete spreadsheets which have most of the data. Anywhere a human generates a data report there is the possibility they could introduce mistakes.
Your agent accidentally creates two of the same record as a result the connector loads these records into the warehouse. A few days later the mistake is rectified in the system. How do you update the warehouse?
I frequently see date formats from different systems including European, American and Universal date time formats as a result I developed in bxp tools specifically to address this complex challenge https://www.bxpsoftware.com/wixi/index.php/Form_-_Cleaning_Date_Time_data
A date can use letters instead of numbers. For example
- Mon and Monday,
- Feb and February,
- Q1 representing a business quarter
Money amounts from Germany and Russia swap commas and full stops when writing amounts. https://language-boutique.com/lost-in-translation-full-reader/writing-numbers-points-or-commas.html
A connector takes time to build and need to remain fixed for their term of their use for the reason that the warehouse needs consistent clean data.
Why size matters
Without getting into the technical specifics of it, it takes more space and effort to process a date if it is in the format 1st February 2017. It is far more efficient to store the data as 2017-02-01 in terms of bits of data in the machine.
A warehouse is expected to store millions if not trillions of pieces of data. In order to do this it needs to know how much space to allocate. When you one or two size doesn’t really matter but when you get to larger scales size drastically impacts speed and processing times.
Open text fields like comments are almost useless to a warehouse as categorising and sifting comments for quantifiable data is difficult. Instead numbers, yes / no, money type data is far more suited to a warehouse. That is not to say a warehouse can’t handle that type of data, it just needs to be specifically optimised for it.
Data Mining / Machine Learning
What is an algorithm?
An algorithm is a set of rules for solving a problem. They are the steps the computer can follow and there are many algorithms for a computer. Some algorithms are more famous than others but the most common one a programmer learns to build are ones for sorting numbers. The bubble sort algorithm is a way of sorting a list of numbers in a way that a computer can do in simple steps.
Data warehouse algorithms are complicated algorithms that can be performed usually on very large sets of data.
Data Mining types
There are a number of areas here to be considered. There are algorithms in each area which can used on the data to achieve the following effects.
Classification
Essentially putting records into groups. You have a fair idea of what those groups are before you start. For example in insurance is this customer a high risk or a low risk customer? You know the groups you just want to put them you just want the computer to do it for you.
Clustering
Is more exploratory. You are looking to see are there groups in the data? For example in supermarkets, if someone buys diapers what else might they buy? You may find a group or might not.
Regression
Classification and Regression are similar but at their core different. Classification is about predicting a label (high risk / low risk) and regression is about predicting a quantity. There is more detailed discussions here https://machinelearningmastery.com/classification-versus-regression-in-machine-learning/
Association Rules
The are about finding interesting associations between items within the data. Similarities are guaranteed to be found unlike clustering which may end up with no clusters. By the term interesting you may think of things being very similar or being very dissimilar.
Machine learning
Classificiation and Regression are considered supervised as you know what you have an idea of the grouping before you start.
Clustering and Association Rules are unsupervised as you’ve no idea, if anything, you might get out of the end of the process.
Machine learning is allowing these algorithms to enable the system to make decisions on its own. A light hearted explanation is available here.
https://chatbotnewsdaily.com/machine-learning-the-mystery-solved-f16936376cd0
In order for machine learning to work it has to make mistakes and then learn from them.
Luckily you don’t have to know how the algorithms are programmed, you can just use them, fire them at your data and get some results. Which can lead to very interesting results which can lead to new marketing promotions, save money on areas that don’t work and discover new products and opportunities.
My experience with the subject

I have lectured Advanced Database Technologies
http://courses.it-tallaght.ie/index.cfm/page/module/moduleId/4851
I have also lectured Enterprise Database Technologies which has evolved and expanded into Applied Machine Learning
http://courses.it-tallaght.ie/index.cfm/page/module/moduleId/4803
P.S. Before you ask, no I won’t do your assignments for you. 🙂 Sean or Barry would never forgive me.
[/read]





